오늘의 TIL 목차 (22. 09. 19)
- 리스트
- 임시 객체
리스트
[ 리스트 ]
: 노드 기반의 시퀀스 컨테이너 - 벡터와 동일한 방법으로 사용
[ 벡터와 리스트의 차이점 ]
[1] 리스트 사용 가능 함수 ( 벡터 사용 X )
@. push_front(원소);
: 배열의 가장 맨 앞에 원소를 삽입할 수 있다
@. pop_front(원소);
: 배열의 가장 맨 앞의 원소를 삭제할 수 있다.
@. splice();
: 이어붙이기?
- lt2에서 iter2이 가리키는 곳에 lt1의 모든 원소를 잘라 붙입니다.
* 리스트만 갖고 있는 함수 *
@. sort( (조건자) ); // 알고리즘 sort(begin, end, 조건자)와 다르게 매개변수 X
: 리스트.sort()시 디폴트로 오름차순 정렬을 한다.
@. reverse(); // 리스트명.reserve()
: 현재 정렬의 역순으로 정렬을 해주는 함수
[2] 리스트는 대괄호 연산자 사용 불가 (=임의접근, 즉 Index 접근 불가)
=> 벡터는 배열 기반 컨테이너, 리스트는 노드 기반 컨테이너이기 때문
[3] 벡터는 임의 접근 반복자, 리스트는 양방향 반복자
=> 임의 접근 반복자는 +=, -=을 사용할 수 있지만 양방향 반복자는 사용 불가
=> begin()에서 위치를 2칸 이동하고 싶다면 iter++; iter++;로 해줘야 함. (iter+=2 불가)※ sort 알고리즘은 배열 기반 시퀀스 컨테이너만 보유, 따라서 노드 기반 시퀀스 컨테이너인 리스트는 알고리즘 sort는 보유하지 않고 멤버 함수로 sort로 보유하여 사용
벡터 & 리스트
[ 시간 복잡도 비교 ]
[ 벡터 ]
1. 삽압/삭제 : O(1) 상수 시간복잡도
- 원소의 개수와 상관없이 back에 push, pop 되기 때문
2. 중간 삽입/삭제 : O(n) 선형 시간복잡도
- 원소가 많을수록 중간 삽입/삭제 시 이동해야 할 원소의 수가 증가하여 시간 비례하여 증가
3. 탐색 : O(1) 상수 시간복잡도
- 인덱스 접근으로 해당 번호의 원소로 바로 탐색 가능
4. 조건에 의한 탐색 ( 순차탐색 ) : O(n) 선형 시간 복잡도
- 모든 원소를 탐색해야 함으로 원소의 개수에 따라 시간 비례함
=> 일반적으로 많이 사용됨
[ 리스트 ]
1. 삽압/삭제 : O(1) 상수 시간복잡도
- 원소의 개수와 상관없이 노드가 front, back에 추가되므로 상관 없음
2. 중간 삽입/삭제 : O(1) 상수 시간복잡도
- 노드 기반이므로 중간 삽입/삭제 시 포인터가 가리키는 주소만 변경되면 돼서 상관없음
3. 탐색 : O(n) 선형 시간복잡도
- 노드끼리 다음 노드의 주소를 가리키고 있는 형식이기 때문에 순차 탐색을 할 수 밖에 없음
4. 조건에 의한 탐색 ( 순차탐색 ) : O(n) 선형 시간 복잡도
- 모든 원소를 탐색해야 함으로 원소의 개수에 따라 시간 비례함
=> 중간 삽입/삭제 시 유리▶ push, pop 시 주의사항
: ( iter = 컨테이너명.begin(), 컨테이너명.end() != iter ; ++iter ) 처럼 iter를 기준으로 한 for문 조건식일 경우 해당 반복문 안에서 push, pop을 한다면 컨테이너 종류, 삽입/삭제 위치에 따라 end() 값이 변경되어 원하는 결과 도출 X
// vector<int> vecInt; list<int> listInt; 가 선언되어 있다 가정
[ 컨테이너.end()가 아닐 때까지 돌리는 for문 안에서 push, pop시 발생하는 문제점 ]
[1]
for문 안에서 push_back() 또는 pop_bakc()하면 end()값이 계속 변경되어
end() 기준을 순회 불가능
* 리스트
for (auto iter = listInt.begin(); listInt.end() != iterEx; ++iterEx)
listInt.push_back(10); // 끝에 추가될 때마다 end 위치 달라짐 -> 오류
for (auto iter = listInt.begin(); listInt.end() != iterEx; ++iterEx)
listInt.pop_back(); // 끝 원소가 삭제될 때마다 end 위치 달라짐 -> 오류
* 벡터
for (auto iter = vecInt.begin(); vecInt.end() !- iter; ++iter)
vecInt.push_back(10); // 뒤에 추가할 때마다 end()위치 변경되어서, end() 기준으로 for문 불가능
for (auto iter = vecInt.begin(); vecInt.end() !- iter; ++iter)
vecInt.pop_back(10); // 끝 원소 삭제될 때마다 end()위치 변경되어서, end() 기준으로 for문 불가능
[2]
list의 경우 노드 기반 컨테이너이므로 push_front(), pop_front() 시
end()위치는 변경되지 않아 end() 기준으로 for문 수행 시 정상 작동
* 리스트
for (auto iter = listInt.begin(); listInt.end() != iterEx; ++iterEx)
listInt.push_front(10); // 리스트는 노드 기반이라 앞에 추가되어도 end 위치 변한 없음, 가능
for (auto iter = listInt.begin(); listInt.end() != iterEx; ++iterEx)
listInt.pop_front(10); // 리스트는 노드 기반이라 앞에 추가되어도 end 위치 변한 없음, 가능
=> end()가 아닌 다른 기준 (size_t를 이용한 횟수 기준)으로 하는 for문 안에서는 push, pop 시 정상 작동▶ 구조체가 담긴 벡터, 리스트 정렬
#include <vector>
#include <list>
#include <algorithm>
struct tInfo
{
string sName;
int iNum;
};
tInfo Return_Info()
{
static auto i = 0; // auto는 1에 의해 자동으로 int 자료형으로 인식
++i;
tInfo tTemp;
tTemp.sName = "다인";
tTemp.iNum = 10 * i;
return tTemp;
}
// 조건자 용도의 함수 객체
class CFunctor
{
public:
bool operator()(tInfo& _A, tInfo& _B)
{
return _A.iNum > _B.iNum; // 내림차순으로 정렬
}
};
void main(void)
{
vector<tInfo> vecInfo;
list<tInfo> listInfo;
// iterator의 경우 auto로 자료형 선언 시 선언과 동시에 초기화
// 컨테이너명.begin() / end()로 값을 넣어줘야 컴파일러가 자료형 판단 가능
auto veciter = vecInfo.begin();
auto listiter = listInfo.begin();
// 원소 삽입
for (size_t i = 0; 5 > i; ++i)
vecInfo.push_back(Return_Info()); // tInfo를 반환해주는 함수를 통해 push_back
for (size_t i = 0; 5 > i; ++i)
listInfo.push_front(Return_Info());
// 범위 지정 for문을 이용한 출력
cout << "vecInfo" << endl;
for (auto& i : vecInfo) // 0 ~ 5를 차례로 back으로 넣었으니까 오름차순
cout << i.sName << "\t" << i.iNum << endl;
cout << "listInfo" << endl;
for (auto& i : listInfo) // 0 ~ 5를 차례로 front로 넣었으니까 내림차순
cout << i.sName << "\t" << i.iNum << endl;
// 벡터 정렬
CFunctor f; // 함수 객체 이용하기 위해 객체 생성
sort(veciter = vecInfo.begin(), vecInfo.end(), f); // vector를 알고리즘 sort를 이용하여 조건자 f(함수객체) 의하여 내림차순
// 리스트 정렬 - 사용자 정의 자료형이라 정렬 기준 몰라 실패
//listInfo.sort(); // listInfo는 현재 구조체가 들어가있어 정렬 기준을 몰라 sort() 불가
cout << "내림차순 sort 후 vecInfo" << endl;
for (auto& i : vecInfo) // 정렬에 의해 내림차순
cout << i.sName << "\t" << i.iNum << endl;
}
▶ 2차원 리스트
: 리스트는 대괄호 연산자가 존재하지 않기 때문에 2차원 리스트의 경우 iList[0]은 주소가 아닌 값이 추출된다. 즉 iList[0][0]처럼 0,0 위치의 원소를 지정해서 가져오는 것은 불가능하다.
: front()를 +1 또는 ++로 다른 위치의 원소 값을 가져오는 것은 불가능하다. iter로만 접근 가능한 듯하다.
#include "stdafx.h" // <list>, <algorithm> 포함
struct tInfo
{
int iA, iB;
};
tInfo* Create_Info()
{
static int i = 1;
tInfo* pInfo = new tInfo;
pInfo->iA = i * 1;
pInfo->iB = i * 10;
++i;
return pInfo;
}
void main(void)
{
int iArray[3][3] = { 00,01,02,10,11,12,20,21,22 };
list<tInfo*> iList[3];
for (size_t i = 0; 3 > i; ++i)
{
for(size_t j = 0; 3 > j ; ++j)
iList[i].push_back(Create_Info());
}
cout << "\" 일반 2차원 배열 iArray 실험 \"" << endl;
cout << iArray[3] << endl; // 2차원 배열은 하나만 적으면 주소가 나오는 게 맞다.
cout << iArray[0] << "\t" << iArray << endl; // 2차원 배열은 주소 이름 자체와, 0번째 ( 0,0 ) 주소가 일치한다.
cout << iArray[2][2] << endl; // 초기화문 iArray[3][3]은 개수를 뜻하므로 인덱스 기준 마지막 원소는 iArray[2][2]라는 것을 명심해라
//iList[0].sort(); // 디폴트는 오름차순 정렬인데 이거 2차원 배열로 오니까 인식을 못함, 왜지?
cout << "\" List[0] 차례로 출력 \"" << endl;
for (auto& i : iList[0])
cout << i->iB << endl;
cout << "\" List의 front()로 다른 위치의 원소에 접근 불가능 증명 \"" << endl; // front도 전위연산으로 iter처럼 다른 위치의 원소를 출력할 수 있는가
cout << iList[0].front()->iB << "\t" << ++(iList[0].front())->iB<< endl; // 이거는 ++ 하면 front보다 한칸 뒤 원소가 아닌 front->iB의 값이 +1 됨 -> 양쪽 다 적용됨
cout << (iList[0].front() + 1)->iB << "\t" << iList[0].front()->iB +1 << endl; // front() 자체 +1은 쓰레기값, iB + 1 은 해당 값에 +1된 값이 출력
// => 즉 front()를 +1이나 전위 연산을 통해서 다음 위치의 원소로 접근하는 것은 불가능, iter로만 접근 가능한 듯 하다.
}
// 리스트 2차원 배열은 인덱스 연산자가 불가능하기 때문에 iList[0]시 0,0 주소가 아닌 0번 iList 안의 값, 즉 원소인 tInfo*을 뜻함
// vector는 인덱스 연산자 가능으로 iVector[0][0]으로 0,0 의 값을 추출할 수 있지만 iList는 대괄호 연산자 불가능으로 iList[0][0] 자체가 안됨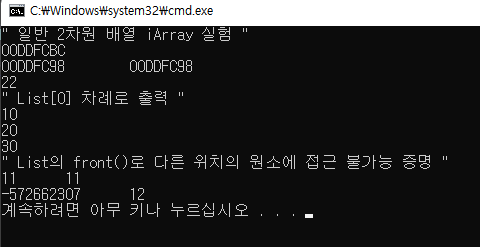
▶ 2차원 벡터
임시 객체
[ 임시 객체 ]
: 임시 메모리 공간에 저장되었다가 해당 라인을 벗어나면 소멸되는 이름이 없는 객체
: 실행 도중에 잠깐만 사용되는 객체로, 소스 코드에도 없는 힙 이외의 공간에 생성되는 것
[ 임시객체 정의 ]
// CDainn 이라는 클래스가 존재할 때
a. 생성자 객체 생성 : CDainn Tem(100); // 객체 이름 존재 O.
b. 임시객체 생성 : CDainn(100); // 객체 이름 존재 X.
[ 임시객체 순서 ]
vector<CPlayer> Vec;
Vec.push_back(CPlayer(10000000));
1. 임시객체 생성
2. 10000000 동적배열 할당
3. 깊은 복사 생성자 호출, 1억개 데이터 복사
4. 임시 객체 소멸자 호출
5. 임시 객체의 멤버 변수 메모리 해제
6. 임시 객체 소멸1) 임시객체는 주소연산자로 주소를 구할 수 없다.
ex ) CDainn *t1 = &CDainn(100); // 에러 발생.
2) 임시객체는 Ivalue가 될 수 없다. ( =의 왼쪽에 올 수 없다.)
ex ) CDainn(100) = 10; // 에러 발생
3) 임시객체는 일반적인 참조가 불가능하다. 그러나, 상수 참조는 가능하다.
ex ) CDainn &ref = CDainn(100); // 에러 발생
const CDainn & ref = CDainn(100); // 실행 가능, 즉 ref가 파괴될 때까지 임시객체는 존재한다.
4) 임시객체는 다음 행으로 넘어가면, 바로 소멸되게 된다. 그러나 참조자에 참조되는 임시객체는, 바로 소멸되지 않는다.☞ 임시 객체는 주로 조건자에 사용된다.
'C++' 카테고리의 다른 글
| [TIL 32장] C++ 11 주요 함수 - 유니폼 초기화, auto, 범위 지정 for문, 람다식, try-catch문 (0) | 2022.09.22 |
|---|---|
| [TIL 32장] 트리 & 해시 자료구조, map(feat. unordered map, multimap), mutable (0) | 2022.09.22 |
| [TIL 30장] 벡터 함수(feat. 2차원벡터), 알고리즘(feat. 조건자) (1) | 2022.09.19 |
| [TIL 29장] 컨테이너 함수(feat. deque), 반복자 (0) | 2022.09.15 |
| [TIL 28장] STL 개론(feat. 자료구조), 컨테이너, 시간 복잡도, 벡터 (0) | 2022.09.14 |

